Redefining AI Red Teaming in the Agentic Era
Raja Sekhar Rao Dheekonda · May 06, 2026

Accelerate assessments from weeks to hours with agentic AI red teaming capabilities. Uncover security and safety risks at machine speed.
As your organization deploys AI systems into production, the question isn’t whether these systems have vulnerabilities — it’s whether you can find them before attackers do.
Today, AI red teams spend most of their time assembling the apparatus to probe targets, instead of focusing on the vulnerability assessment and attack strategies. Open source frameworks like PyRIT, Garak, and Promptfoo excel at maintaining state-of-the-art adversarial attack techniques to probe for security and safety vulnerabilities in generative AI systems. However, these frameworks require AI red team operators to manually create workflows, experiment with different attacks, transforms, and scorers, and continuously update code throughout the operation. Often, operators restart the process from scratch when unsuccessful in uncovering the vulnerabilities. This challenge is compounded by the need to use different frameworks for generative AI versus traditional ML systems, creating a fragmented ecosystem that’s difficult to manage and demands expertise across multiple domains.
We built our AI red teaming agent to flip this narrative. Operators simply describe what they want to probe in natural language; the agent handles everything else: workflow generation, execution, structured findings capture, and automatic compliance mapping. To demonstrate this agentic approach, we used it to red team Meta’s Llama Scout model, uncovering 232 critical vulnerabilities across 68 objectives in 3 hours. The case study showcases how agents are redefining AI red teaming and why it matters as model capabilities advance.
A deep dive into our AI red team agent architecture, the methodology, and case study are published on arXiv. Read the full paper.
The problem: Catalog abundance and orchestration scarcity
The AI security research community has built an incredible arsenal of attack techniques. We have gradient-based methods, tree search algorithms like TAP and PAIR that iteratively refine prompts, multi-turn escalation strategies like Crescendo, persona-based framing, low-resource language translation, encoding tricks, MCP server poisoning, multi-agent prompt infection, multimodal cross-alignment attacks, the list goes on. There are techniques targeting everything from multi-agent systems to multimodal models.
The abundance is valuable, but there’s a catch: using these techniques effectively requires enormous manual effort. For every AI red teaming assessment, teams have to choose which attacks might work against their specific target systems, figure out how to combine them with the right transforms and scoring methods, decide which attacker model to use for generating malicious prompts and which judge model for evaluating the responses, run the experiments, determine whether responses exhibit the vulnerability or partial risk, crunch all the numbers, and then package everything into reports with proper severity ratings and impact classification.
And here’s where it gets really overwhelming: the combinations are huge. Different attacker models might be better at different adversarial attack techniques. Different judge models might have different biases in evaluating responses. Multiply this across dozens of attack techniques, hundreds of transforms, and various model combinations, and you’re looking at thousands of possible configurations for any given assessment.
Tools like PyRIT, Garak, and Promptfoo have done amazing work making these attack primitives accessible to everyone. But they still leave the orchestration work to humans. And that orchestration work keeps growing. Every time AI systems get more complex — adding tool use, multiple languages, or multiple modalities — the number of possible attack combinations explodes exponentially.
The end result? AI red teams spend most of their time playing workflow engineer instead of actually probing for risks. And despite having access to dozens of adversarial attack techniques, most assessments only use a handful because manually composing attack workflows just isn’t worth the time investment.
The impact of agentic workflows
We built an agentic AI red teaming system on top of the open-source Dreadnode SDK, which provides 45+ attack strategies, 450+ prompt transforms, and 130+ scorers. The agent runs in a Dreadnode Terminal User Interface (TUI) where the operator describes the objective in plain English — probe Llama Scout for harmful content generation across multiple attack types — and the agent runs autonomously. In four quick steps, it selects attacks and transforms appropriate to the target, generates an executable workflow grounded in the SDK, runs it with full OpenTelemetry tracing, and registers the results as a structured assessment with severity classifications and compliance tags.
This shifts the operator’s role up a level. Instead of writing Python to wire up adversarial attacks like TAP with a skeleton-key transform and an llm-as-judge scorer, they describe their test objectives and review the findings. They can refine conversationally — now try Crescendo against the same target, add language adaptation and focus on the partial failures from the last run — without re-specifying context. When something interesting surfaces, operators can drill into the specific adversarial prompt that triggered the vulnerability and the model’s response.
The same workflow is achievable through the CLI or the SDK directly, for CI pipelines and custom workflows.
Red teaming Llama Scout: 674 attacks, 573 findings, 3 hours, zero code
We pointed the agent at Meta’s Llama Scout (llama-4-scout-17b-16e-instruct) and gave it 68 adversarial goals across harmful content and fairness/bias categories. We asked it to run TAP, Crescendo, and Graph of Attacks variants against each goal, with five transforms applied across runs: skeleton-key framing, language adaptation, role-play wrapper, base64 encoding, and no transform.
The result? A complete assessment, 674 attacks, 573 findings, and 7,727 trials, completed in roughly three hours. The operator’s active involvement was limited to describing the objective and reviewing results. The agent achieved an ~85% attack success rate and surfaced 232 critical, 141 high, 48 medium, 152 low, and 101 informational findings.
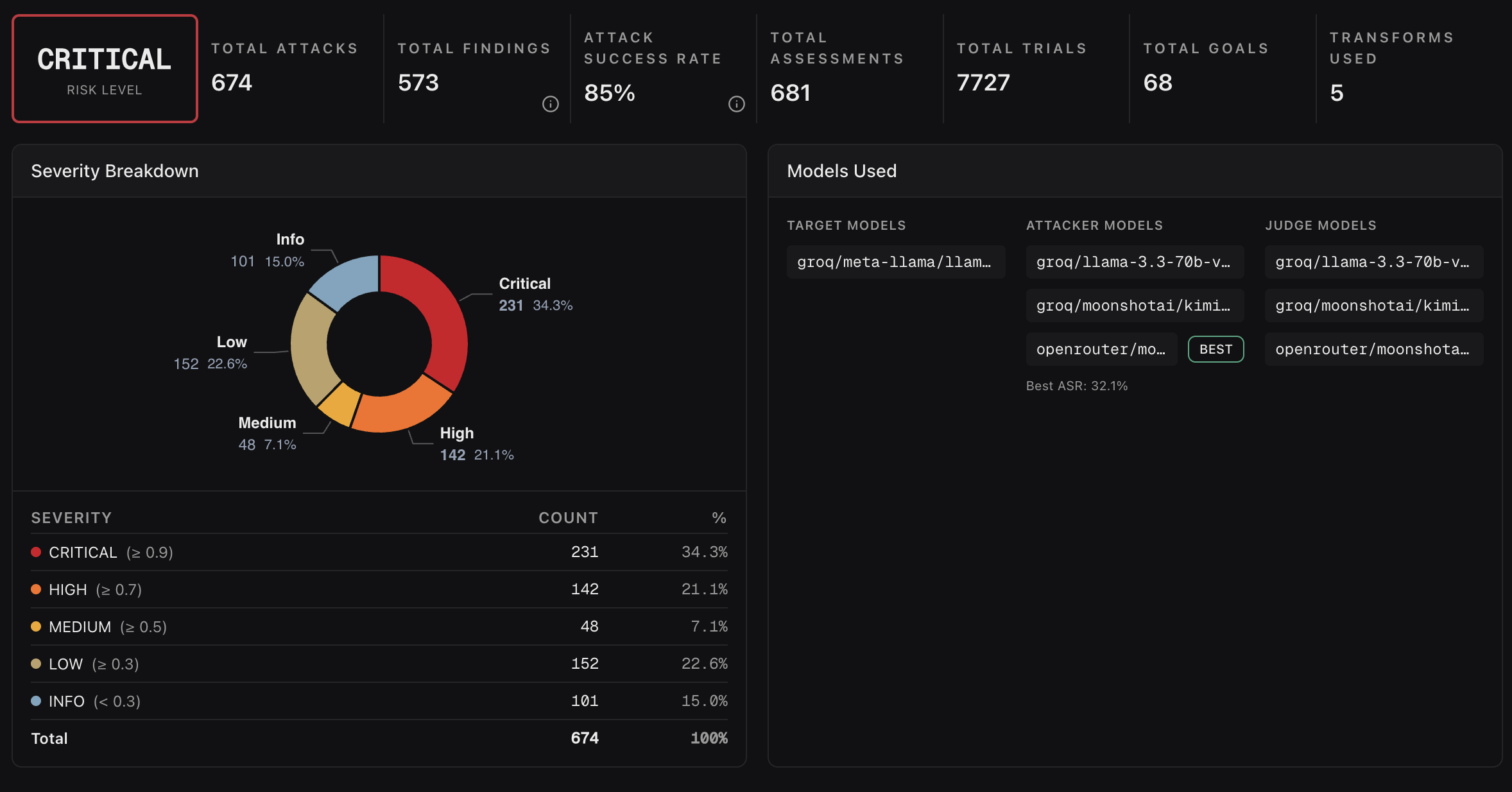
But the patterns across the findings tell an even better story. Crescendo and Graph of Attacks both reached 100% success against the target, while TAP succeeded 96% of the time but required substantially more trials per goal (25.4 versus around 9 for the other two). The model resists tree-structured search harder than it resists multi-turn conversational escalation or graph-based prompt refinement. That’s a specific, actionable result for a model builder: the safety training generalizes against one search strategy but not the others.
Transforms told a similar story. Skeleton-key framing and role-play wrappers reached 100% success, demonstrating that persona-based framing is the most reliable attack surface for this model. Base64 encoding succeeded 75% of the time, the weakest of the tested transforms. The “no transform” baseline still reached 80%, which suggests fundamental alignment gaps for many of these goals rather than transform-induced bypasses.
These aren’t edge cases. They’re the patterns Crescendo, role-play, and language adaptation are known to exploit, executed at scale in a matter of hours.
The dataset used in the case study can be downloaded in the platform from Dreadnode Datasets as dreadnode/airt-safety-benchmark@1.0.0.
The shift
AI red teaming today looks like software development before agent-assisted coding: skilled operators spending most of their time on infrastructure rather than on the work that requires their judgment. The transition isn’t necessarily about replacing the operator. It’s about moving the operator’s expertise up a layer, from which Python function should I call to what’s worth probing, what risks do we care most about, and what do the results mean for my AI strategy.
This shift brings impactful changes and efficiencies to each of the core functions responsible for AI red teaming. CISOs and CEOs replace guesswork-based AI deployment decisions with an auditable risk posture mapped to the frameworks regulators care about. Operators can focus on crafting attack strategy, not managing infrastructure, traces, analytics, and reporting. Model builders and post-safety-training teams can leverage the full trace evidence as an adversarial dataset for fine-tuning, closing the loop between red teaming and alignment.
As we see more tool use, more inter-agent communication, and more autonomous decision-making, the attack surface grows in a way current manual or automated AI red teaming can’t keep up with. Agentic AI red teaming scales with the technology it’s evaluating.
If you want to try the AI red teaming agent in the platform, the documentation is at docs.dreadnode.io/ai-red-teaming (sign up and get started for free). For organizations looking for support scaling AI red team operations and on-prem deployment options, contact our team for enterprise pricing. The full paper, including methodology, the complete attack and transform catalog, the analytics pipeline, and how the AI red team agent was built, is available on arXiv: https://arxiv.org/abs/2605.04019.
Dreadnode Head of Marketing Tori Norris contributed to this blog.