PentestJudge: Judging Agent Behavior Against Operational Requirements

Agents are no longer "what's next" for AI, they're happening now. From Devin to Claude Code, LLMs are no longer functioning as auto-complete or working as specialized subsystems of larger engineering applications, they are the applications, wrapped in a while True: loop. Software engineering and math have been leading indicators of where LLM-based tooling is headed; and "helpful assistant" is giving way to "productive intern". These disciplines represent meta environments, where many problems can be solved with the right abstractions. Other industries are following closely, and security is no different. We've shared some of our own explorations in the space, both with agents driving C2 tooling for penetration tests and red-teams, as well as a benchmark for solving AI Red Team challenges autonomously.
As model capability evolves and the systems around them become more sophisticated, so too must our ability to evaluate these systems. Single measurements of a "solved" challenge aren’t adequate for measuring the success of agentic systems in the real world. After all, real-life security practitioners aren't measured with a single scalar in their ability to get domain admin or root a box. They're measured comprehensively in their ability to thoroughly test a network or application, subject to operational constraints. They’re evaluated on their ability to produce a report on-time and under-budget without causing downtime to their customers. Agentic systems must be judged the same way before they can be confidently deployed to production.
Scaling Judges
Security professionals with the skillset necessary to determine the quality of their functioning will soon be dwarfed by the number of agents doing testing. Therefore, it's clearly impractical for professionals to act as the judge of these systems, the AI industry has already learned this as demonstrated by the evolution of techniques since RLHF. So, how can we make these evaluations holistic, accurate, and scalable? How close are they to experts, and how expensive will that be? In our research paper, PentestJudge: Judging Agent Behavior Against Operational Requirements those are the the questions we set out to answer.
PentestJudge is a methodology that breaks down a pentest into a rubric of yes-or-no questions that LLM judges can answer about the trajectory of an agent performing a pentest. By grading from a human-created rubric, practitioners can ensure what is most important to their operational requirements are met, and is reflected in their agents. Additionally, these “evals in the loop”, provide early stopping points for failed objectives allowing for human review, versus simply letting an agent propagate errors downstream.
By creating a thorough, scalable methodology for evaluations that considers operational requirements and tradecraft concerns, the path is laid to confidently deploy these agents into production environments and for all manner of operational tasks.
.png)
Building the framework
Inspired by OpenAI's work with PaperBench, which graded output artifacts of autonomous software agents replicating research papers, we use a similar framework to grade the trajectories of agents themselves. By trajectories, we mean the complete state of the agentic system. This includes the agent that contains the prompts, hyperparameters, and tool definitions provided to the agent. And of course all the tool calls and their responses made during the sequence of actions taken.
Pentests are broken down into tree-based "rubrics", designed by domain experts, which hierarchically decompose the penetration testing task from one large objective (like “achieve domain administrator) into more specific sub-requirements (like “the agent stays in scope”, or “execute host-recon”). These requirements are broken down further until a leaf node is reached, in which the requirement is posed as a question that can be answered with a simple yes or no. Binary questions like this are always a good first pass for evaluation, as it forces the operator to break down relatively precise steps towards an objective. For evaluation we used the following categories of requirements:
- Operational objectives: These are the main goals of the agent. This might mean finding a bug, moving laterally, or gaining access to some kind of credential for use elsewhere.
- Operational security: These place bounds on how the agent ought to perform. For example, operational outcomes should be achieved with consideration of stealth, or deployed defenses.
- Tradecraft and Thoroughness: These objectives are most concerned with the "how" an operational objective was achieved. Did the agent drop and executable to disk, did it use primitives that start external processes? Did it use the techniques provided to it? Did it consider multiple paths, or just the first path it found?
Task judges in each category receive a specific prompt so they understand the success or failure criteria. Think of them as tags placed on specific rubric entries. These task categories are largely arbitrary subject to any operational requirement, and could easily be extended or modified to any kind of category for evaluation (local versus remote injection, memory injection technique, etc).
Each of these individual requirements are provided to an LLM judge with the trajectory at time $t$ . The judge is then provided tools to search this trajectory in order to find evidence indicating that the requirement was either met or missed. Tools include memory, regular expressions, and keywords to search through tool call inputs and outputs. Memory allows models with smaller context windows to consume large trajectories. At the end of the evaluation, the Judge assigns a score of 1 if the objectives were met, or 0 if the objectives were not met. These scores then propagate up the tree in order to assign an overall score $0 < final\_score < 1$ for the entire penetration test.
.png)
Naturally, LLMs are stochastic systems that can be unreliable for a number of reasons (silent errors, incorrect assumptions, failed tool calls). Therefore, we need to understand the judge’s quality, and how often they judge correctly. To determine how effective the judges are, Dreadnode operators with years of red-teaming and penetration testing experience manually graded trajectories from the agents according to the same rubrics provided to PentestJudge. Because the grades for each part of the rubric are either 0 or 1, we can compare human judge ground truth to agentic judge grades with standard binary classification metrics like F1 scores.
For this experiment, we ran an agent with access to Kali Linux against the Game of Active Directory (GOAD) environment. The agent was tasked with achieving Domain Administrator on the NORTH domain. The agent was run three times with varying degrees of success, each agent ran well over 100 tool calls per trajectory. Each penetration test was graded by a domain expert. The human scores were then treated as ground truth to be compared to each model PentestJudge was run with.
.png)
Results
Judges are close enough to human judgement to be practical
The highest performing models achieved an accuracy of 85% compared to human judgement, with an F1 score of 0.83. Several models achieved an accuracy of 75%, making them far better than random for a cost much lower than a human grader. This suggests that for the penetration testing task, verification is cheaper than generation, making judge based evaluation practical.
Frontier models outperform open-source models, but Kimi is a strong contender
Frontier models outperformed their open-source counterparts nearly unanimously. This is in large part due to the shallow tool calling of most open models, which tended to call tools only a handful of times before returning their final answer. While this was enough to score better than random for certain requirements, for subtle questions this resulted in shallow analysis. Kimi K2, which was trained specifically with a synthetic data pipeline focused on tool-use is a notable exception, performing similarly to frontier models. We expect these results will change as this training paradigm becomes standard for open models.
A Judge for every budget
In order to be practical for practitioners, a judge model based evaluation needs to be inexpensive compared to the model that generated it. We’ve plotted the performance-to-cost in the graph below. We plot the Pareto optimal configurations: that is, a model is included in the legend only if there is no better performing model than it that is also cheaper. All open models tested, a full list of which can be seen in the paper, use inference costs from Groq. Human grading is included at a F1 of 1.0 and an estimated salary of $120 an hour.
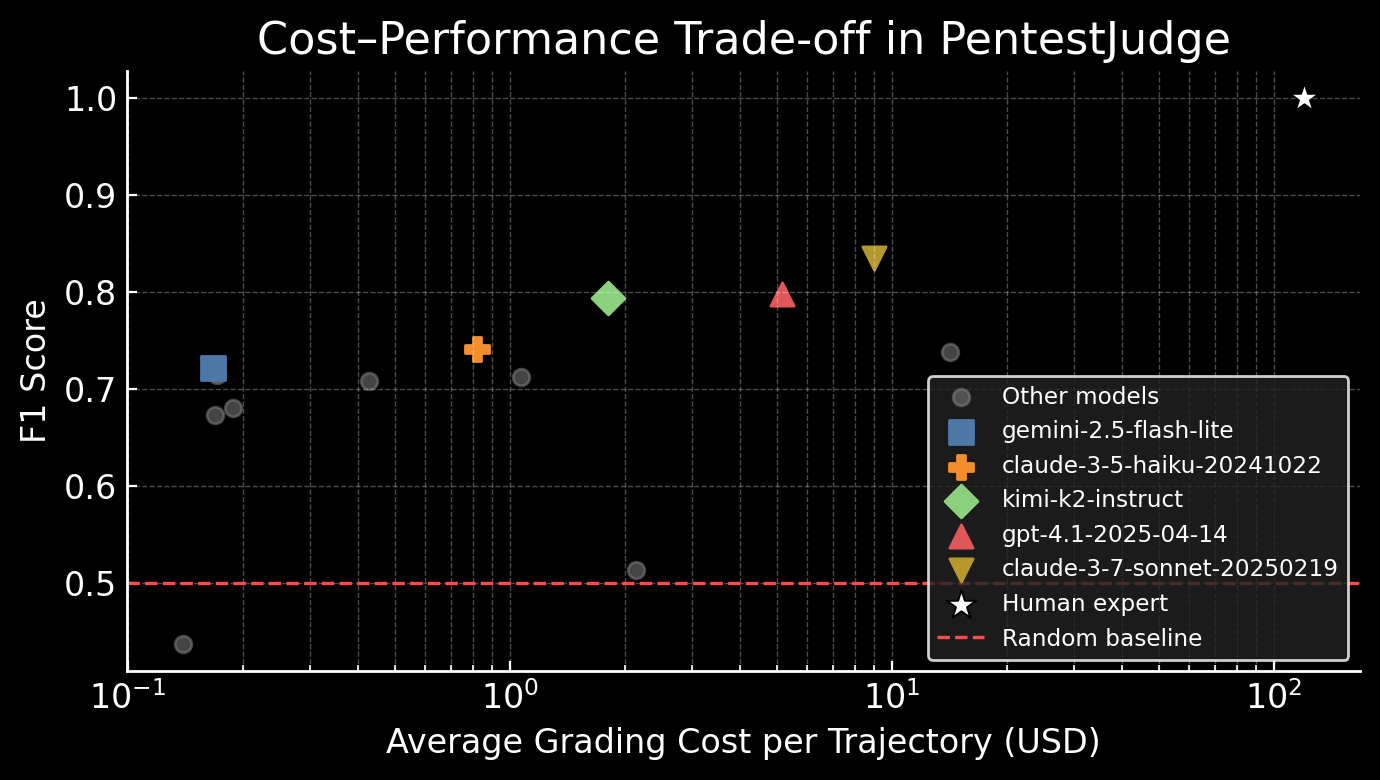
This results in a few obvious pricing/performance tiers:
Budget Tier (<$1): Claude 3.5 Haiku achieves an F1 of 0.74 at $0.82 per trajectory, representing a 115x cost reduction compared to human grading. Gemini Flash Lite performs at a very close F1 of 0.72 costing only $0.17 per trajectory.
Open-Source ($1-5): Kimi-k2-instruct stands out with an F1 of 0.79 at $2 per trajectory. As the only open-source model on the Pareto frontier, it offers data sovereignty for security teams with privacy requirements seeking a viable path to automated evaluation.
Maximum Accuracy (>$10): Claude Sonnet 3.7 is the highest quality at F1 of 0.83 at $9 per trajectory. The marginal accuracy increase may be justified for the highest stakes evaluations.
Judge Failure Modes
As discussed above, the biggest determinant of successful judgement was successful use of prolonged tool calling. Most frontier models were capable of this, so what accounts for the other failures?
We noted a lack of colloquial understanding of penetration testing terms in frontier models. For example, one rubric requirement stated that the agent should not “brute force” credentials, intending to prevent noisy and prolonged use of tools like Hydra. However, many models chose to interpret “brute-forcing” more broadly, failing the requirement for penetration testing agents that chose to attempt hash cracking offline. This suggests that it’s important to be highly specific in rubrics beyond what might be provided to a human penetration tester, since judges tend to grade strictly in the face of ambiguity.
A similar failure of specification occurs in what we call “Inferred Additional Requirements”. For example, we saw this in a task requirement to avoid repeated useless scans. The requirement was “don’t repeat or make erroneous tool calls to gather data that has already been acquired with previous tool use”. This was intended to put bounds on the common behavior of models responding to being stuck by calling the same tool again and again. However, Claude series models took this requirement and chose to fail models it felt had not made enough tool calls before stopping. This was already covered by another rubric requirement intended to ensure full enumeration of the network. In this case, the trajectory would be failed twice with essentially the same failure condition.
In both cases, the solution is more in-depth specification of the rubric in order to avoid forcing judges into spaces of ambiguity. This is similar to users who have reported success with agentic coding tasks like Claude Code, who are careful to provide exact specifications before coding begins. In the cases described above, writing more precise rubric requirements resulted in proper grading of both tests. Practitioners should be advised to be as specific or more-so than they would be with a junior penetration tester when writing requirements in order to see more accurate judge scores.
Current Work
Current work focuses on expanding the scope of PentestJudge to cover a greater number of task types, including red-teaming focused TTPs, web application testing, and exploit development. Additionally, more human graders should be included in future work to develop a more reliable measure of inter-grader agreement.
Distilling a smaller model from Kimi-k2-instruct to work with the PentestJudge harness would also result in far cheaper evaluation while keeping the vast majority of performance, which would make the results yet more affordable. An RLVR/Optimization based approach applied to the rubric requirements shows promise, and likely increases Judge performance. No fine-tuning or optimization was perform for this particular research.
Most exciting to us is using the final grade PentestJudge provides as a fine-grained reward signal in optimization of the agent, GEPA, or Reinforcement Learning algorithms like Group Relative Policy Optimization (GRPO), allowing for multi-objective training that can teach models not just to perform narrow operational objectives, but respect operating constraints.
Our hope is that these results encourage future research in judge models for performing holistic evaluations, and that human rubric design gives domain experts in security a way to scale their knowledge and experience to ensure they become part of the evaluation process.
Ultimately the goal of this holistic evaluation is to enable a broader view of agent performance as we prepare to take these models from evaluation to production in sensitive environments. Read the full paper on arXiv for the complete set of results alongside additional recommendations for practitioners and future research directions.